
高光谱成像联合低场核磁共振技术检测盐渍海参含水量
背景
水分含量(Moisture content, MC)在海参腌制过程中起着重要作用。较高的MC会导致胶原纤维断裂,使海参在储存过程中更容易受损,较低的MC会降低海参的口感和营养价值。准确控制海参腌制过程中MC的含量,对海参的口感品质和商品价值具有重要意义。
大量研究使用高光谱成像(Hyperspectral imaging, HSI)和低场核磁共振(Low field nuclear magnetic resonance, LF-NMR)研究水的迁移和变化并预测MC。HSI是一种用于探测浅水表面物理和化学性质的快速、无损监测技术。LF-NMR是另一种流行的无创检测技术,用于监测食品中水分状态的变化和水分迁移。低频核磁共振之所以有效,是因为当电磁脉冲(Electromagnetic pulse, EMP)在垂直方向辐射时,氢质子由于能量从低能级到高能级的转变而处于不稳定状态,而当EMP消失时,这一过程是可逆的。对于海参浅层表面复杂的棘皮结构和内部复杂的腔体、体壁等结构,HSI和LF-NMR联合检测可以更准确地预测MC。
深度学习(Deep learning, DL)网络可以减少模型对人类经验的依赖,提高模型的泛化能力。CS(Cuckoo search)优化算法通过提取数据的显著特征实现降维,可以有效提高基于小样本空间和低类间差异数据的模型性能。因此,本研究基于HSI和LF-NMR数据,采用DL网络和CS优化算法联合构建预测模型,对盐渍海参的MC进行预测分析。
具体研究目标如下:(1)分别针对HSI和LF-NMR数据构建基于变种CS算法的MC深度学习预测模型;(2)通过探索模型的性能,确定了HSI和LF-NMR的*优模型;(3)根据*优模型和核磁共振成像(Magnetic resonance imaging, MRI),分别基于HSI和LF-NMR数据可视化MC分布;(4)构建基于融合数据的MC的Fusion-net DL(FDL)预测模型,并与以往基于单一数据的模型进行比较,选择*终的*优模型。
试验设计
大连工业大学王慧慧教授团队利用Image-λ-N17E近红外高光谱成像系统(江苏双利合谱公司)获取了510个不同腌制处理下的海参高光谱影像(图1a)。高光谱数据由350张640×803像素的单波段光谱图像组成,波长范围为934.8 ~ 1710.6 nm。如图1e所示,将盐渍海参样品置于核磁共振分析仪(Niumag电气公司)中进行LF-NMR测,得到如图1f所示的横向松弛曲线。每个腌制周期取同一样品进行MRI分析,通过自旋回波成像序列获得MC在不同腌制时间的氢质子MRI(图1g)。
数据的强相关性可能导致“维度诅咒”,有必要对冗余的高维信息进行降维处理。使用CS算法选择特征,如图1h所示。针对不同的应用领域,CS有不同的变体,本研究使用的三个变体分别为Traditional-CS(TCS)、Binary-CS(BCS)和Chaotic-CS(CCS)。
将降维后的数据输入到相应的模型中进行训练,选择*优模型(图1i),实现MC分布变化的可视化(图1j)。在本文中,MC的预测模型包括基于高光谱数据的单独DL模型、基于LF-NMR数据的单独DL模型和基于HSI和LF-NMR数据的FDL模型。对于HSI数据,DL框架中使用了两个1D卷积层,分别包含32个和64个卷积核,大小为1×3(图2a)。
对于LF-NMR数据,DL框架的总体结构与上述HSI相同。但对于LF-NMR曲线,除了纵向数值差异外,吸收峰也有明显的横向位移。因此,LF-NMR数据比HSI数据更复杂,需要更多的卷积核来提取潜在特征来解决这种复杂的情况。因此,如图2b所示,将大小为1×3的64、128和256个卷积核组成的三个卷积层应用于LF-NMR预测模型。对于HSI和LF-NMR,分别建立了基于整体和降维数据(W和DR)的MC预测深度学习模型,并讨论了它们之间的性能差异。
图2c给出了MC融合预测模型的融合策略。将约简后的两种特征分别放入相应的DL框架中,在flatten层和dense层之间添加concatenate层,将两种特征合并。

图1 研究流程图
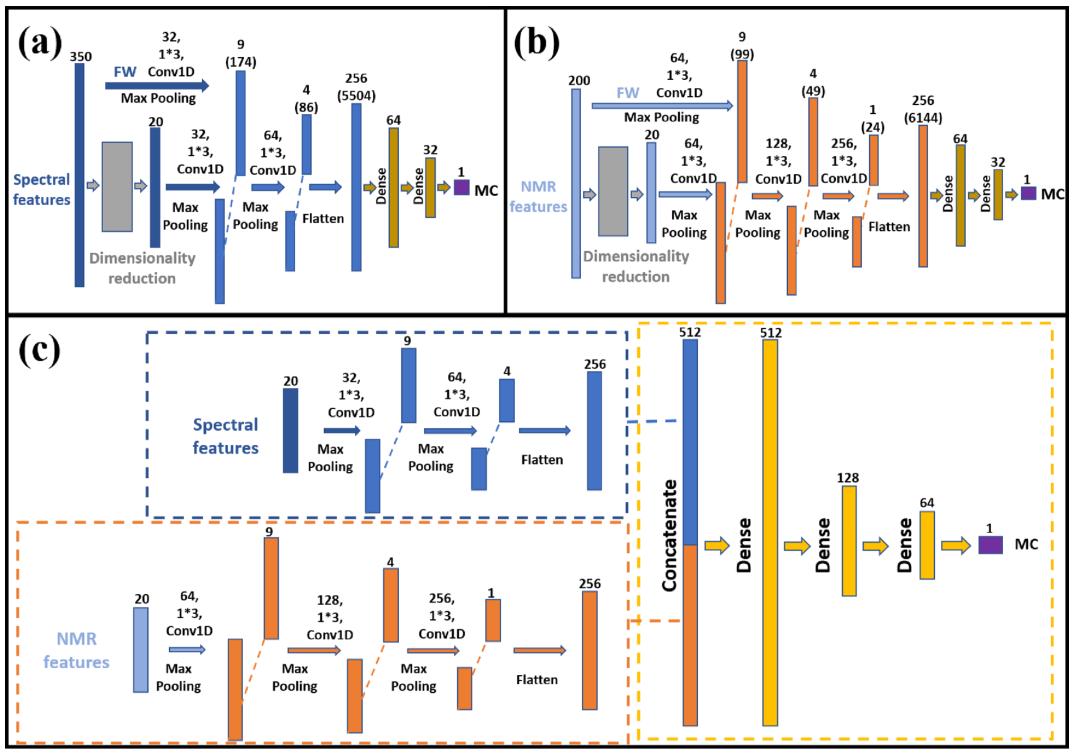
图2 多种深度学习模型。基于光谱的深度学习模型(a);基于LF-NMR的深度学习模型(b);融合深度学习模型(c)。
结论
图3为不同腌制阶段样品的光谱反射率变化图。在图3a中,不同腌制时间样品的光谱反射率变化趋势大致一致。但在1100 nm之前,0 h样品的反射率值与其他样品相差很大。可以得出结论,腌制过程的持续时间将是导致反射率变化的重要因素。在960 nm、1190 nm和1430 nm处可以观察到三个明显的吸收峰。在图3b中,平均光谱反射率呈现出与腌制时间相关的变化规律,在960 nm左右,随着腌制时间的延长,反射率显著增加,说明样品内部水分有所降低。在1190 nm左右,反射率逐渐增大,说明海参样品中的脂质和蛋白质含量在腌制过程中损失较慢。

图3 不同腌制阶段海参样品的平均光谱反射率曲线
海参样品在各腌制周期的CPMG弛豫衰减曲线和T2弛豫光谱如图4所示。如图4a所示,样品中质子的衰变速率随着腌制时间的延长而增加,在前三个腌制阶段变化较大。由此可以推断,在腌制初期,样品中大量水分流失,样品中氢质子的含量同时下降,导致质子衰变速率明显增加。在腌制过程后期,样品的内部和外部几乎接近渗透压平衡,导致MC变化很小。如图4b所示,在未腌制(0 h)的海参弛豫曲线上存在3个质子弛豫峰,分别为束缚水(T21)、不动水(T22)和游离水(T23)。腌制处理后,T21先减少后消失,T22和T23逐渐减少。随着腌制时间的增加,海参样品中的束缚水向右迁移,逐渐变为不动水。不动水向左移动并压实。随着时间的推移,游离水也会转移到剩余的地方,很容易丢失,从而创造了一个抑制微生物活动的环境,这有利于海参的储存。
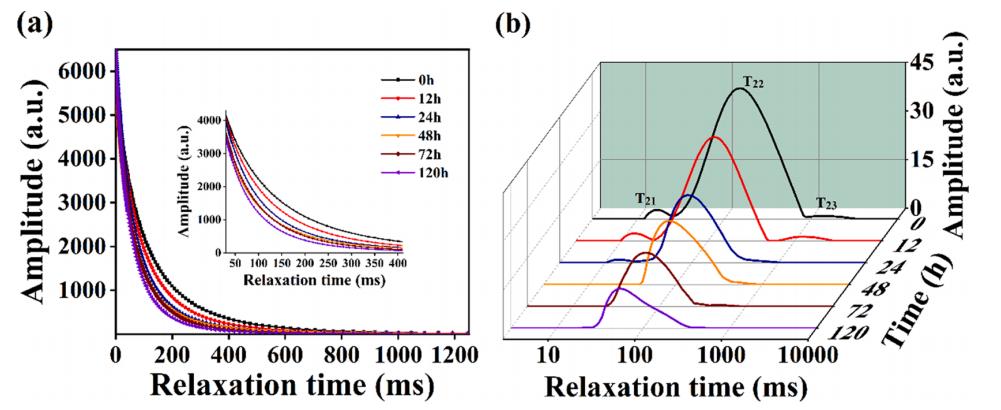
图4 LF-NMR数据
结合CS降维算法和1D-CNN DL框架,构建了基于HSI、LF-NMR信息的MC预测模型。图5为基于全部特征的MC估测模型精度图。证明了DL框架适用于基于HIS以及LF-NMR数据的MC预测。将HSI中所有波长和LF-NMR中时间点对应的数据输入到FDL框架中进行MC计算。预测效果如图5e和图5f所示,可以看到W-FDL具有明显的优势。这表明两类数据在训练中是相辅相成的,即在单一数据类型中,不可避免的会出现个别数据的异常导致某一样本的预测失败,但同一样本的两类数据几乎不可能同时出现异常,这为预测模型的准确性提供了保证。

图5 HSI-W-DL模型在校准集(a)和预测集(b)、LF-NMR-WDL模型在校准集(c)和预测集(d)、W-FDL模型在校准集(e)和预测集(f)的模型精度。
图6为三种不同降维算法在HSI数据集中选择的具体波段,用虚线表示。TCS选择的20个波段如图6a所示,在整个波长范围内分散,既提供了丰富的信息,又降低了相关性。图6b为BCS算法选取的159个波段,虽然在1000-1050 nm、1200-1250 nm和1500-1600 nm波长范围内所选波段的密度高于其他地区,但其分布基本覆盖了整个波长范围。这意味着所有的特征都包含在选择的波段中,BCS通过大幅减少数据量来降低计算成本,而不是消除非显著特征,这可能不利于提高模型的泛化能力,并可能导致过拟合现象。图6c显示了CCS选择的20个特定波段,所选波段在全波长范围内的分布比TCS更加离散。在优化过程中,前20次迭代HSI-TCS-DL和HSI-CCS-DL的MSE远小于HSI-BCS-DL,50次迭代后HSI-BCS-DL的MSE没有减小。同时,自第10次迭代以来,HSI-CCS-DL的MSE约为HSI-TCS-DL的一半,证明混沌映射算法在寻找*优解方面优于随机算法。
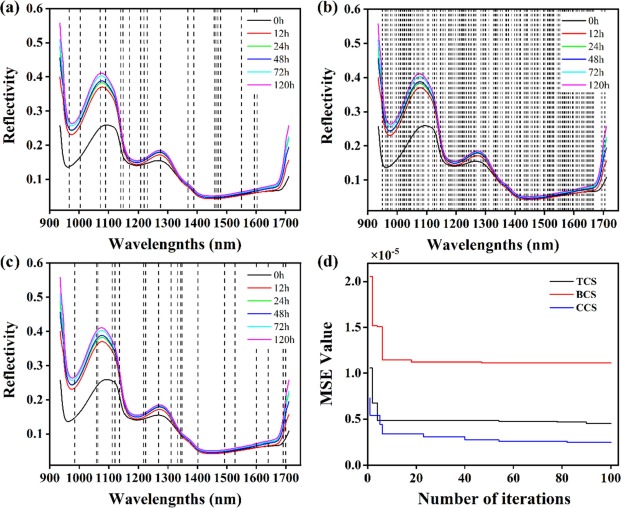
图6 选自HSI-TCS-DL(a)、HSI-BCS-DL(b)、HSI-CCS-DL(c)模型的具体波段以及HSI-TCS-DL(d)、HSI-BCS-DL(e)、HSI-CCSDL(f)模型的MSE衰减。
图7显示了HSITCS-DL、HSI-BCS-DL和HSI-CCS-DL模型的性能。与全数据模型相比,特征约简后的数据点更收敛于45°直线,对较低MC值的预测效果提高*为显著。与HSI-W-DL相比,HSI-TCS-DL模型的准确性和稳定性得到了显著提高,表明降维后的数据更具代表性。虽然HSI-BCS-DL的性能比HSI-W-DL略有提高,但在数据适应性和预测精度方面不如HSI-TCS-DL。与HSI-TCS-DL模型相比,HSI-CCS-DL的性能有所提升,这是因为在CCS降维算法中使用混沌序列初始化种群,有效地解决了模型因随机初始化而陷入局部*优解的问题。根据上述对比,在HSI数据中,选择CCS作为*优降维算法,确定HSI-CCS-DL模型为*优模型。
基于HSI-CCS-DL的MC可视化如图8所示。可以清晰地显示样品浅表面同一阶段内不同点的MC差异以及不同阶段间的变化规律。海参没有腌制时,基本呈蓝色,说明其MC*高。随着腌制时间的延长,中间区域的颜色由蓝色变为绿色,*终变为黄色,同时黄色域逐渐向边缘扩展。
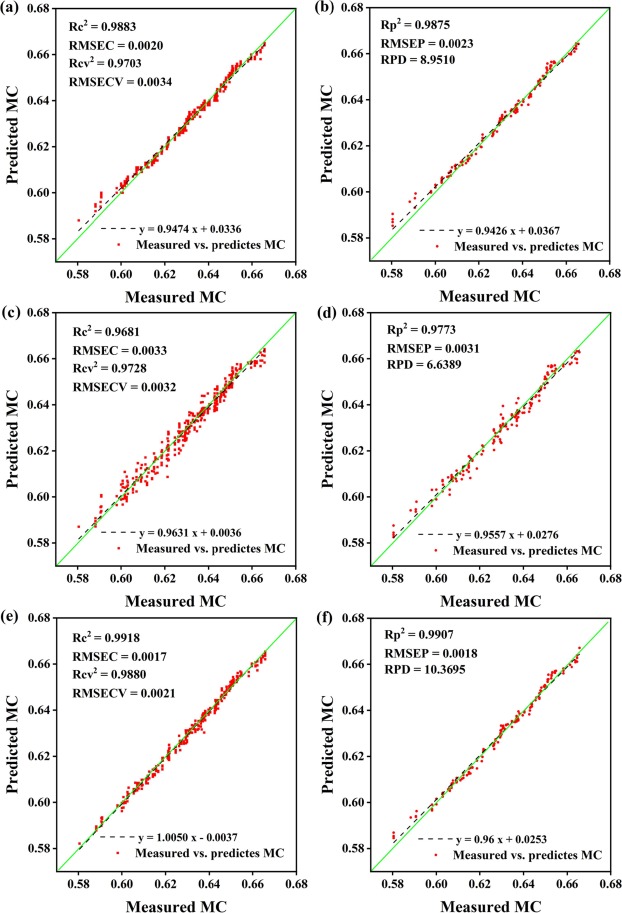
图7 HSI-TCS-DL模型在校准集(a)和预测集(b)、HSI-BCS-DL模型在校准集(c)和预测集(d)、HSI-CCS-DL模型在校准集(e)和预测集(f)的模型精度。

图8 基于HSI-CCS-DL模型的海参腌制过程MC分布可视化
图9详细描述了LF-NMR-TCS-DL、LF-NMR-BCS-DL和LF-NMR-CCS-DL的特征选择以及MSE衰减结果。CCS算法是*优的,BCS算法提前收敛,但三种算法的结果差异减小。对于LF-NMR数据,选择CCS作为*优降维算法,并确认LF-NMR-CCS-DL为*优模型,这与HSI数据的结果一致。

图9 利用LF-NMR-TCS-DL(a), LF-NMR-BCS-DL(b), LF-NMR-CCS-DL(c)模型选择的波段以及其MSE衰减(d)。
结合HSI和LF-NMR数据的FDL框架用于海参MC预测。由于前文确定CCS降维算法效果*好,因此选择CCS和FDL框架构建CCS-FDL模型。如图10所示,校正集和预测集的R2均达到0.99。在数据点的分布上,图10a中的训练集的数据点更加紧凑,更接近真实值,图10b中的预测集也出现了同样的情况。FDL框架的优异性能可能是由于HSI和LF-NMR数据之间的互补优势,即在检测过程中,同时使用HSI和LF-NMR数据可以大大减少单个数据不准确造成的预测偏差。各模型的比较分析结果见表1。可以看出,对于FDL框架,基于HSI和LF-NMR数据的模型的性能都得到了显著提高,特别是在整个数据模型中,并且CCS-FDL模型使用40个特征输入实现了*佳性能。
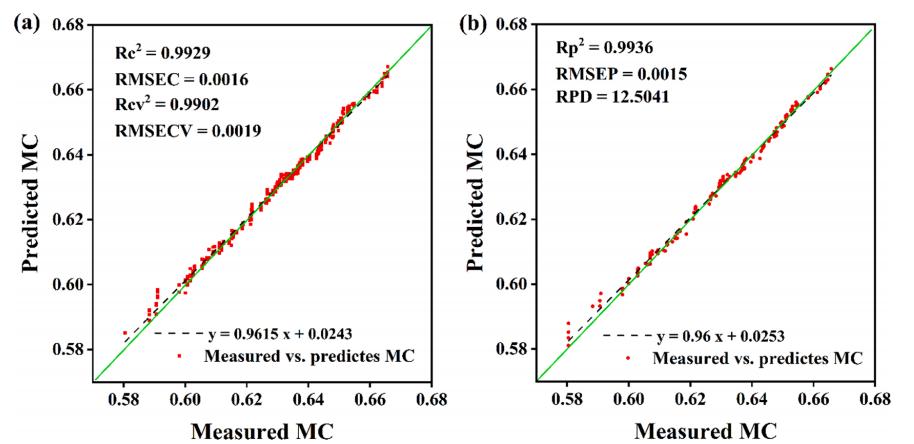
图10 在HSI和LF-NMR数据集中使用CCS提取特征的FDL模型的预测结果
表1 基于FW、TCS、BCS和CCS的深度学习模型性能

作者信息
王慧慧,博士,大连工业大学机械工程与自动化学院教授,博士生导师。
主要研究方向:基于机器视觉的智能检测研究、装备数字化设计。
参考文献:
Zeng, F., Shao, W., Kang, J., Yang, J., Zhang, X., Liu, Y., & Wang, H. (2022). Detection of moisture content in salted sea cucumbers by hyperspectral and low field nuclear magnetic resonance based on deep learning network framework. Food Res Int, 156.
https://doi.org/10.1016/j.foodres.2022.111174